
i18n Part 1: How We Built Zip's i18n Infrastructure



Introduction
Zip is a procurement orchestration platform used by companies and vendors worldwide. As we expanded internationally, we needed to localize the entire product. Not just translating a few labels, but systematically internationalizing our React/Flask monolith with strings living in Python, TypeScript, Thrift, and Protobuf.
This post covers the foundational decisions for our static translation infra: which frameworks we chose, why we bundle translations instead of fetching them over the air, how our extraction and catalog pipeline works. We’ll also dive into our composite string registry that bridges the gap between static translations and user-generated content.
Why This Is Hard
Our stack presented a few challenges that made off-the-shelf solutions insufficient:
- Dual runtime: React frontend + Flask backend, both serving user-facing strings. Whatever we chose needed to work across both.
- Strings everywhere: Not just in
.pyand.tsxfiles. We have ~1,500 static strings defined in Thrift and Protobuf schema files that get code-generated into both Python and TypeScript. - Strings persisted in the database: System-generated messages like "Cloned from: {config_name}" are stored in Postgres. These are a mix of static templates and dynamic user input, which we call "composite strings."
- Async workers: Celery tasks and Kafka consumers send notifications and emails. These run outside Flask's request context, so locale detection needs to work outside a logged-in user session.
Framework Choices: Lingui + Flask-BabelEx
Frontend: Lingui
We evaluated three major React i18n libraries: react-i18next, react-intl, and LinguiJS. We chose Lingui for several reasons:
Macros over lookup keys. With i18next, you write t('approval.status.pending') and maintain a separate JSON file mapping keys to strings. With Lingui, you can write the string directly:
// Lingui — the string IS the source of truth
<Trans>Pending approval</Trans>
// i18next — requires a separate JSON catalog
{t('approval.status.pending')}
Lingui macros compile at build time into hashed IDs, so the bundle is small (~3kb gzipped) and you never have the "naming things" problem. Duplicate strings are also automatically merged, saving translator effort and cost.
PO file output. This was the deciding factor. Lingui extracts to .po files, the same format Flask-BabelEx uses on the backend. This meant we could use a single translation management system (Crowdin) with a unified workflow for both frontend and backend.
ESLint plugin. Lingui ships with custom ESLint rules that catch common mistakes: unwrapped strings, incorrect macro usage, missing imports. This became critical during our large-scale migration (covered in Post 2).
Backend: Flask-BabelEx
Flask-BabelEx is a fork of Flask-Babel that supports multiple Flask extensions with separate translation domains.
The core API is straightforward. It’s all built over GNU gettext (as we found most i18n libraries to be), where we load in compiled message catalogs and perform lookups at runtime:
from i18n.utils import t
# Basic translation
label = t("Review overdue approvals")
# With variables using .format() over f-strings (explained below)
label = t("{queue_name} SLA has increased by {time}").format(
queue_name=queue_name, time=time
)
We wrap gettext() in our own t() function that adds None-safety and pseudo-locale support for QA testing.
Why .format() and not f-strings
This tripped us up early on. In TypeScript, tagged template literals let you intercept interpolation:
// JS: the t tag receives static parts + dynamic values separately
t`Hello ${userName}, welcome to ${orgName}`
Python f-strings don’t offer such grace. When Python evaluates f"Hello {name}", it immediately produces "Hello Alice", a fully expanded string with no way to recover the template which we extracted for localization. So we enforce .format() to defer interpolation until after we’ve localized:
# This silently breaks extraction and runtime lookup
t(f"Hello {name}")
# ✅ Babel extracts "Hello {name}" as a key; .format() fills in at runtime
t("Hello {name}").format(name=name)
We enforce this with a ruff lint rule (f-string-in-get-text-func-call) that flags any f-string inside a translation call.
Bundling vs Over-the-Air (OTA)
The two main approaches for delivering translations:
Bundling bakes translations into the application at build time so strings ship with the code.
OTA fetches translations at runtime from a CDN, decoupling translation updates from deployments.
We chose bundling mainly as Flask-BabelEx doesn't support OTA. If the frontend used OTA but the backend used bundling, we'd have two completely different translation update workflows, two different caching strategies, and two different failure modes. The cognitive overhead wasn't worth the OTA benefit of faster translation iteration.
In practice, our deployment cadence is fast enough compared to our translation QA process that bundled translations don’t act as the bottleneck. New strings are extracted in CI, uploaded to Crowdin, auto-translated, and downloaded at deploy time.
Frontend: Webpack Code-Splitting Per Locale
On the frontend, each locale's message catalog is a separate webpack chunk. When the app bootstraps, it loads only the active locale:
// Dynamic import — only the active locale is loaded
const loadCatalog = async (locale: string) => {
switch (locale) {
case 'de-DE':
return import(
/* webpackChunkName: "locale-de-DE" */
'../locales/de-DE/messages'
);
case 'es-ES':
return import(
/* webpackChunkName: "locale-es-ES" */
'../locales/es-ES/messages'
);
// ... other locales
}
};
// At app startup
const messages = await loadCatalog(userLocale);
i18n.loadAndActivate({ locale: userLocale, messages });
This means a German-speaking user never downloads French translations. The base English bundle stays lean.
The Extraction Pipeline
String extraction is the process of scanning source code and producing a catalog of translatable strings.
Backend Extraction
We use pybabel extract with custom keyword configuration:
pybabel extract -F babel.cfg \\
-k t \\
-k lazy_gettext \\
-k register_pattern:1 \\
-k ngettext_flexible:1,2 \\
-o locales/messages.pot .
The -k register_pattern:1 is worth calling out. It tells Babel to extract the first argument of our composite string registration function (explained below). This means composite templates are automatically added to the translation catalog alongside regular strings.
The output is a .pot (Portable Object Template) file, basically a master list of all extractable strings. Per-locale .po files are then initialized from this template, and translators fill in the target-language strings.
Frontend Extraction
yarn lingui extract # Scans for t`` and <Trans> macros
yarn lingui compile # Compiles .po → .ts message catalogs
Lingui's extractor finds all t tagged templates and <Trans> components in the source, generates hashed IDs, and outputs .po files. After translation, lingui compile produces TypeScript modules that webpack can bundle.
File Structure
website/
├── locales/ # Backend catalogs
│ ├── messages.pot # Master template
│ ├── en_US/LC_MESSAGES/messages.po
│ ├── de_DE/LC_MESSAGES/messages.po
│ ├── es_ES/LC_MESSAGES/messages.po
│ ├── fr_FR/LC_MESSAGES/messages.po
│ ├── ja_JP/LC_MESSAGES/messages.po
│ └── ...
├── assets/locales/ # Frontend catalogs
│ ├── en-US/messages.po
│ ├── de-DE/messages.po
│ └── ...
└── crowdin.yml # Source/target file mappings
The Composite String Registry
This is maybe the most architecturally interesting piece of our static string i18n infrastructure, also acting as the bridge between static string translation and the UGC translation system we'll cover in Post 3.
The Problem
Many strings we persist to the database aren't purely static or purely user-generated. They're composites, a mix of static template and dynamic user input:
# This gets stored in the database as:
# "Leo requested more info on Q4 Budget Review"
comment_title = f"{user_full_name} requested more info on {approval_name}"
When a German-speaking user later reads this from the database, we need to translate the template ("requested more info on") while preserving the dynamic parts (the user's name, the approval name). But all we have in the database is the fully expanded string.
The Solution: Register at Module Load, Match at Runtime
We maintain a singleton registry of composite string templates. Each template is registered at module load time with its pattern and the entity type + field it applies to:
from i18n.utils import i18n_registry
# Registered when the module loads, before any requests
CLONED_NAME = i18n_registry.register_pattern(
"Cloned from: {name}",
("process_node", "name")
)
# Later, when persisting:
def clone_config(source):
new_config.create().name(
CLONED_NAME.format(name=source.name)
).save()
The register_pattern call does two things:
- Adds the template
"Cloned from: {name}"to the Babel extraction catalog (via the-k register_pattern:1flag) - Registers a compiled regex pattern keyed by
(object_type, field)in the in-memory registry
When we create the new config, the persisted string will just be “Cloned from: Parent config” , as no lookups have yet occurred.
At runtime, when a string is read from the database, the registry then attempts to decompose:
def extract_and_translate(input_str, object_type, field):
# Try composite pattern matching
patterns = i18n_registry.get_patterns(object_type, field)
for pattern in patterns:
match = pattern.regex.match(input_str)
if match:
variables = match.groupdict()
return t(pattern.template).format(**variables)
# If no match found, return original
return input_str
In cases of multiple templates found, we score based on the greatest amount of static content (meaning we can lookup the translations for as much as possible from an already localized template).
Performance-wise, regex matching over even 1,000 patterns completes in single-digit milliseconds. We haven't needed to optimize further, but plenty of libraries exist should our pattern count balloon.
This translation lookup is autogenerated alongside our base object fetchers from database also. That is, if on our db schema we annotate a string field with i18n_enabled = True, then we will autogenerate a localized fetcher to enable product engineers to easily call as needed:
class Node:
...
def name(self) -> str:
return super().name()
def i18n_name(self) -> str:
return extract_and_translate(self.name(), Node, "name")
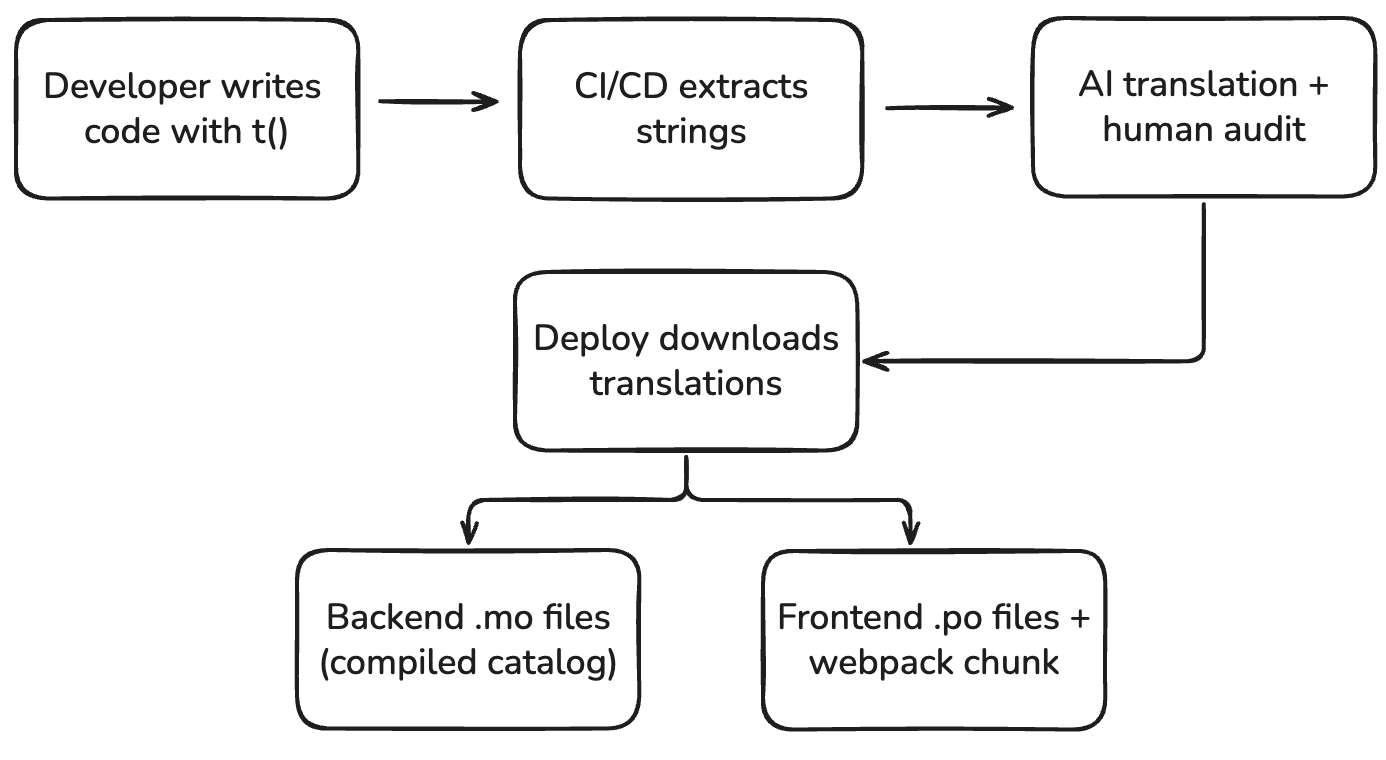
The Crowdin Pipeline
Crowdin is our translation management system. The workflow:
- Extract: CI runs
pybabel extractandyarn lingui extracton every commit - Upload: Extracted
.potand.posource files are pushed to a Crowdin branch matching the environment (staging, qa, prod) - Translate: Crowdin auto-translates via AI (configured by our set LLM providers). Human translators from our vendor (Translated) review certain high-priority strings.
- Download: At deploy time, the Docker build downloads the translated files from the matching Crowdin branch
- Compile:
pybabel compileproduces.mofiles for the backend;yarn lingui compileproduces.tscatalogs for the frontend
The branch-per-environment model means staging can have experimental translations that don't affect production, and QA can test specific locale fixes without a full deploy cycle.
What's Next
In Post 2, we'll cover how we actually migrated tens of thousands of strings, using AI-assisted code transformation that evolved from 70% accuracy to 90%+, codemods for Thrift and Protobuf, and the QA pipeline that caught what the AI missed.
In Post 3, we'll dive into our UGC translation system, a completely different architecture using LLM-based translation, Kafka and CDC pipelines, and caching strategies to translate user-generated content on the fly.