
i18n Part 3: Translating User-Generated Content


Introduction
In Posts 1 and 2, we covered how we internationalized Zip's static strings (all strings Zip controls). But for a procurement platform used by multinational enterprises, that's only half the problem.
The other half is in User-Generated Content (UGC). Think comments, custom questions, or vendor responses that customers create in their language. When a German-speaking admin creates a workflow called "Genehmigungsworkflow für IT-Beschaffung" and a French-speaking approver needs to understand it, we need real-time, high-quality translation.
This is a fundamentally different problem from static string i18n. There's no catalog to extract from, no build-time compilation, and no Crowdin workflow. UGC translation happens at runtime, must work for any input in any language, and needs to be fast enough that users don't notice.
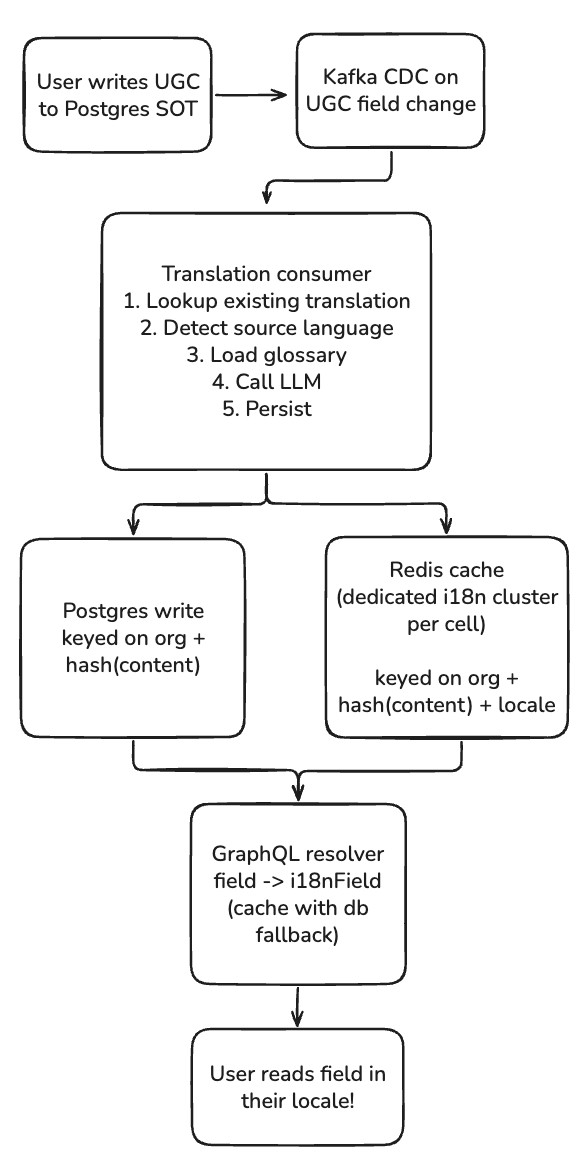
This post covers the architecture we built: LLM-based translation with glossary enforcement, a Kafka CDC pipeline that triggers translations asynchronously, and the lookup architecture and caching strategy that makes serving translations blazingly fast.
Unlike static strings, UGC can't be pre-translated or looked up from a catalog. The input is arbitrary, created at runtime, and different per organization. We need a translation system that handles any text, in any source language, to all target locales, with consistent terminology.
Architecture Overview
The I18nField: Making Any Entity Field Translatable
The core design goal was: a product engineer on any team should be able to make a field translatable without understanding the translation pipeline. No Kafka configuration, no cache keys, no LLM prompts. One annotation, and it works.
We considered several approaches before landing on this:
- Manual resolver wiring. Each team writes their own translation lookup for each field. This is how many i18n systems work, and it doesn't scale. With 500+ entity types across dozens of teams, we'd be writing integration guides and debugging translation bugs forever.
- Middleware/decorator approach. A GraphQL middleware that intercepts all string fields and attempts translation. Simpler for teams, but too blunt: it would translate field names that shouldn't be translated (IDs, codes, slugs) and miss fields that should be (nested objects, computed strings). It also makes performance characteristics invisible.
- Schema-level annotation with code generation. The approach we chose. A single
i18n_enabled=Trueon the Ent schema field, and the code generator handles everything downstream.
When an entity schema field is annotated with i18n_enabled=True, we would then autogen:
- A
derived_localecolumn to store the detected source language - An async
i18n_prefixed accessor that handles locale detection, cache lookup, and fallback - A GraphQL resolver that automatically routes to the localized variant
class NodeSchema:
name = StringField(
description="Vendor display name",
i18n_enabled=True, # example annotation.
)
...The generated code handles the full resolution path: check if the user's locale matches the source language (skip translation entirely), check the Redis cache, fall back to the database, and if nothing exists, return the original text and fire an async event to generate the translation for next time.
On the GraphQL layer, consumers are automatically routed to the localized variant of any base field:
async def resolve_attribute(root, attribute_name):
...
# use the i18n_* variant if exposed on the ent
i18n_attrname = f"i18n_{attribute_name}"
resolved_name = (
i18n_attrname
if hasattr(root, i18n_attrname)
and callable(getattr(root, i18n_attrname))
else attrname
)
return getattr(root, resolved_name)The result: teams across the company have made dozens of fields translatable without filing a single question in our support channel. They add one annotation and the field is immediately served in the user's locale.
The Async Translation Pipeline
Locale column
We use the derived_locale column as a heuristic for if translations exist for a field. On writes, we clear out the associated derived_locale , also autogened on the ent setter
def set_name(self, val):
self.name = val
self.name_derived_locale = NoneOn reads, if the derived_locale column matches the current user’s chosen language, we don’t need to perform any translation lookups. If the value is missing, we enqueue a job to a similar consumer as detailed below.
Kafka CDC Consumer
Translations are triggered asynchronously via Change Data Capture. When a UGC field is updated in Postgres, a Kafka consumer detects the change:
# Simplified consumer logic
async def handle_field_update(event):
# Only translate if we haven't detected a locale yet
# (derived_locale == None means new/updated content)
if event.field_derived_locale is not None:
return
await translate_and_persist(
org_guid=event.org_guid,
object_type=event.object_type,
object_guid=event.object_guid,
field_name=event.field_name,
content=event.field_value,
)This allows translation derivation to happen in the background after a user saves content. There's a brief window where content appears untranslated, but for our use case (enterprise workflow configuration) this is acceptable. Admins configure workflows once and users consume them repeatedly.
The Translation Flow
async def translate_and_persist(org_guid, content, ...):
# 1. Check composite string registry (from Post 1)
# If it's a known pattern, extract and translate template
registry_match = i18n_registry.match(content, object_type, field)
if registry_match:
return translate_composite(registry_match)
# 2. Check if we already have a translation for this content
content_hash = hash_content(content)
existing = await EntTranslation.load(content_hash)
if existing:
return existing.translations
# 3. Load glossary for this organization
glossary = await load_glossary(org_guid)
# 4. Translate via LLM
response = await translate(
content=content,
glossary=glossary,
target_locales=SUPPORTED_LOCALES,
)
# 5. Persist translation and populate cache
await EntTranslation.create(
ugc_translation_key=f"{org_guid}:{content_hash}",
derived_locale=response.derived_language,
derived_locale_confidence=response.derived_language_confidence,
translations={t.locale: t.translation for t in response.translations},
)
await populate_redis_cache(org_guid, content_hash, response)The composite string registry check (step 1) is the bridge from Post 1. If a database string matches a known composite template (like "Cloned from: {name}"), we decompose it and translate the static template via the existing catalog instead of calling the LLM. This saves cost and ensures consistency with the static translations.
Storage and Caching
Content-Hash Keyed Storage
Translations are stored in a Translation entity, keyed by {org_guid}:{content_hash}. Content-hash keying means identical strings across the same organization share a single translation record. If two workflows both have a field with value "Pending Review", they share the translation.
Lazy Persistence: Write with TTL, Remove on First Read
The naive approach is to translate every UGC field update and persist the translations permanently. However, most translations are never read. An admin might update a workflow config field 10 times before it's finalized. Each intermediate value triggers a translation that no one may ever request.
Our solution is lazy persistence and re-derivation. When a translation is first generated, we translate only to the company level language with a one-week TTL. If no user ever requests that translation, it quietly expires. But the first time a user actually reads the translated field, we remove the TTL, promoting the translation to permanent storage:
async def on_translation_read(org_guid, content_hash, locale):
translation = await EntTranslation.load(f"{org_guid}:{content_hash}")
if translation and not translation.accessed:
# First read: promote to permanent storage
await translation.update(accessed=True, ttl=None)This keeps the translation table bounded to content that users actually consume, without any manual cleanup jobs. Further, if we perform a translation lookup and the language is not found, we enqueue a job to retranslate to ensure eventual i18n support.
Dedicated Redis Cluster with Cache Pollution Protection
We maintain a dedicated Redis cluster for translation caching, separate from our main application cache. This prevents translation cache operations from competing with session or query caches.
The subtlety is in how we handle bulk operations. Export jobs, audit packages, or other large async jobs can touch tens of thousands of translated fields in a single request. Without protection, a single export would evict the hot translations that interactive users depend on.
We use Redis's CLIENT NO-TOUCH command to solve this. When a bulk operation reads translations, we enter a no-touch context that prevents those reads from affecting the LRU eviction policy:
@asynccontextmanager
async def no_touch_i18n_cache():
"""Prevent bulk reads from polluting the translation cache."""
await i18n_redis.execute_command("CLIENT NO-TOUCH ON")
try:
yield
finally:
await i18n_redis.execute_command("CLIENT NO-TOUCH OFF")
# Used in export/audit paths
async def export_request_data(request_guid):
async with no_touch_i18n_cache():
# These reads won't evict interactive users' cached translations
translations = await bulk_fetch_translations(request_guid)This means a nightly audit export won't degrade translation latency for the user who opens the app the next morning.
LLM-Based Translation
We use large language models for translation instead of traditional machine translation NMT APIs (Google Translate, DeepL, etc.). The main reason is for glossary enforcement and context awareness. LLMs can be instructed to respect domain-specific terminology in a way that API-based MT struggles with.
Batch Translation
We translate to all target locales in a single LLM call rather than making separate calls per locale. The prompt instructs the model to translate batches of input text into all supported locales simultaneously, returning a structured list of translations with confidence scores and derived languages to reduce API cost and latency.
Glossary-Aware Translation
Procurement has domain-specific terminology. "PO" means Purchase Order, not Post Office. "RFP" is a Request for Proposal. Customers may have their own terms too. "Beschaffungsanfrage" might be their preferred German term for "procurement request" instead of the more literal translation.
The Glossary System
Admins can manage translation glossaries through the webapp, adding base terms, their languages, and the overridden translations for each language of choice.
When translating, we inject matching glossary terms into the LLM prompt:
Translate the following text to all target locales.
GLOSSARY (you MUST use these exact translations when
the base term appears):
- "Purchase Order" → de_DE: "Bestellung",
fr_FR: "Bon de commande"
- "Approval" → de_DE: "Genehmigung",
fr_FR: "Approbation"
If a glossary term has no entry for a specific locale,
translate it naturally. Do NOT carry over the English
term to non-listed locales.
Input text: "Your Purchase Order has been sent for
Approval."On response, we can verify the glossary entry overridden translations are present.
Further, admins can also exclude specific fields from translation entirely, which is useful for fields that contain codes or technical identifiers.
Bridging Static and UGC: The Blurry Line
In practice, the boundary between static strings and UGC is fuzzy. A field might contain:
- A system-generated value like "Default: Vendor" (composite string, translate via registry)
- A purely user-written value like "Bürobedarf Genehmigung" (UGC, translate via LLM)
- A value that happens to exactly match a static translation key like "Pending" (could be either)
Our resolution order:
- Exact static match. If the string exists in the Babel catalog, use the catalog translation. This is the cheapest and most reliable path.
- Composite pattern match. If the string matches a registered template, decompose and translate the template via catalog, keeping dynamic parts intact.
- LLM translation. If no pattern matches, treat it as pure UGC and translate via LLM.
This layered approach means the LLM is only called for genuinely novel user content, keeping costs predictable and leveraging the high-quality human-reviewed catalog translations wherever possible.
Major learnings
Glossary utilization >> LLM model ability. Procurement terms are specific to organizations, and organizations have
What's Next
- Document translation: translating uploaded PDFs and attachments, not just string fields
- Glossary auto-population: using translation patterns to suggest new glossary terms to admins
- Generalized index: means to lookup base content from translations. This will unblock natural language to access objects across all languages, regardless of which initial locale was written.